

Riccardo Silini| Universitat Politècnica de Catalunya, Barcelona


___________________________________________________________________________________________
Hablamos con: Riccardo Silini, doctorando de CAFE
Viernes 11 de febrero 2022
Los eventos climáticos extremos dejan tremendos impactos en la sociedad. Solo en 2021, tal y como detalla la Organización Meteorológica Mundial en su ‘Estado del Clima de 2021’, los impactos de los eventos climáticos han sido enormes. La temperatura hizo que lloviese por primera vez – en vez de nevar – en el hielo de Groenlandia. Los glaciares canadienses sufrieron un rápido deshielo. Canadá y las zonas cercanas de EE. UU. sufrieron una ola de calor en las que se llegó a casi 50ºC. El valle de la muerte de California registró 54.4 ºC como pico en una ola de calor y muchas partes del mediterráneo tuvieron temperaturas récord. En China, la cantidad de lluvia que habitualmente cae en varios meses, cayó en apenas unas horas y diversas partes de Europa se inundaron, causando docenas de muertes y daños millonarios. En Sudamérica, la reducción en el caudal de los ríos impactó la agricultura, el transporte y la producción de energía de numerosos países.
Por eso, investigar y comprender cómo se producen estos fenómenos extremos es de vital importancia. Nos permite estar más preparados, predecirlos con mayor precisión y en definitiva tener más control sobre su impacto. Una de las iniciativas de las que formamos parte busca investigar sobre eventos climáticos extremos, para así mejorar nuestra comprensión sobre ellos. Se trata de CAFE, una ITN: una red que une a investigadores, industria y conocimientos especializados en climatología, meteorología, estadística y física no lineal. El objetivo es entrenar a diversos diversos doctorados, cuyas tesis están relacionadas con el clima extremo. En total, 20 instituciones entre beneficiarios y socios, lideradas por el Centre de Recerca Matemática. Dentro de esta red, desde Predictia funcionamos como “hogar de acogida” durante un periodo de tiempo para algunos de los doctorandos de la red, y así complementar su formación y que puedan ejecutar proyectos concretos.
Hoy entrevistamos a uno de estos doctorandos, Riccardo Silini, a punto de defender su tesis. Su investigación gira en torno a dos temas: el primero es un fenómeno climático muy específico, conocido como la oscilación Madden-Julian (los detalles, más adelante), y un método estadístico para analizar la causalidad entre diferentes fenómenos. Para hablar de todo ello, quién mejor que el propio Riccardo.
Antes de meternos en harina, cuéntanos un poco sobre ti.
Vengo de Suiza, donde obtuve me licencié e hice un máster en Física en física en la EPFL. Me centré principalmente en las redes complejas, las neurociencias teóricas y la inteligencia artificial. Actualmente estoy haciendo mi doctorado en el proyecto ITN CAFE en la UPC en Barcelona, que gira en torno a la previsión de los extremos climáticos sub-estacionales.
Una parte de tu investigación gira en torno a la oscilación Madden-Julian. ¿Cómo explicarías este fenómeno para alguien que se encuentra este término por primera vez?
Se trata de un fenómeno que afecta a una zona muy concreta del mundo: desde el oeste de África hasta el océano Pacífico. Es un patrón atmosférico cuyo efecto directo es dejar precipitaciones anómalas y su característica principal es que tiene dos zonas: una con más precipitaciones de lo habitual y otra con menos.
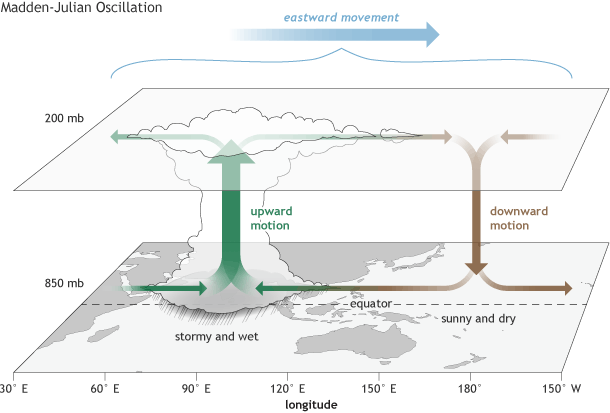
La oscilación de Madden-Julian deja dos zonas diferenciadas, una más lluviosa y otra más seca, que se desplaza hacía el este | Fuente: cazatormentas.net
Además de las propias lluvias que genera la oscilación, ¿por qué es importante predecir su comportamiento?
Además de dejar más o menos precipitaciones, influye en los monzones de verano del oeste de África y de la India. Y yendo más allá, tiene una conexión bidireccional con El Niño (El Niño es influido por la MJO y al revés).
Lo que hace que está oscilación de Madden-Julian sea más complicada de predecir es que a veces está activa y a veces inactiva, como si tuviera un interruptor. Para indicarnos si la MJO está activa o no, miramos un índice, llamado RMM, que sirve para indicarnos si este fenómeno está activo o no. Mi tesis consiste en mejorar la predicción de este índice, utilizando un enfoque de Machine Learning.
¿Podrías contarnos un poco más de detalle?
Para aquellas personas que quieran meterse en detalles técnicos, hay un paper que hemos publicado en npj Climate and Atmospheric Science. En este paper aplicamos dos enfoques para la predicción. El primer enfoque es de Machine Learning puro: empleo un tipo concreto de redes neuronales, intentando mantener unas redes neuronales lo más simple posible. Como es de esperar, el desempeño de estas redes por sí solas no supera al de los modelos climáticos. Esto es normal, porque los modelos climáticos llevan detrás toda la física de la atmósfera, y por tanto simulan la realidad. Sin embargo, este enfoque de Machine Learning sí que supera a otros métodos más simples. Además, comparado con los modelos climáticos, que son computacionalmente muy pesados, el enfoque de Machine Learning es mucho más ligero.
Este primer enfoque encaja muy bien en una de las eternas discusiones que vemos en el ámbito de la Inteligencia Artificial: la rivalidad amistosa entre la gente que opina que es mejor utilizar modelos numéricos y los que opinan que es mejor aplicar Machine Learning, Deep Learning u otras técnicas. ¿En qué parte de este espectro te situarías?
Como todo, depende de la aplicación concreta. En mi caso, para las simulaciones de clima y meteo… creo que es mejor tirar por la calle de enmedio y dejar que cada técnica aporte su mejor parte. Me explico: los modelos numéricos simulan muy bien la física que hay detrás de fenómenos atmosféricos, y nos dan una información muy valiosa. Por tanto, tiene sentido que usemos estos modelos como una primera aproximación, en vez de gastar tiempo y recursos en que una red neuronal “aprenda de cero” estos fenómenos. No tiene sentido poner este peso de aprendizaje en la red cuando ya conocemos esa física.
Este es justo el segundo enfoque que exploramos en el paper. Tomamos de partida un modelo numérico, e intentamos mejorar sus predicciones, post procesando con Machine Learning. En concreto utilizamos el mejor modelo numérico que hay actualmente, desarrollado por el ECMWF, que tiene la mejor skill de predicción para la oscilación de Madden-Julian. Entonces tomamos una red neuronal (feed-forward neural network) y la entrenamos para que corrija los resultados del modelo. El resultado es un post proceso que mejora la predicción del modelo numérico y que también es mejor que otros tipos de postprocesado más clásicos, como una regresión lineal múltiple.
Otro aspecto interesante es que hemos visto que también mejora un aspecto muy concreto de la predicción: cuando la oscilación de Madden-Julian está a punto de entrar en el continente marítimo, la física se vuelve más compleja, y la habilidad de predicción de los modelos numéricos cae. Es justo en este punto en el que la corrección con Machine Learning tiene el mayor efecto, porque llega a corregir bastante bien esta caída del skill.
En resumen, creo que lo más útil es dedicar recursos a mejorar las dos cosas: mejorar los modelos numéricos a medida que vamos descubriendo nuevos aspectos de la física que hay detrás; y mejorar el post proceso de Machine Learning, que cubren esa última distancia entre modelos y realidad, para hacer predicciones más precisas.
Vamos a cambiar de tema, para hablar de otro de los focos de interés de tus investigaciones: la causalidad. ¿Nos puedes explicar un poco de dónde parte tu interés?
En nuestro día a día, normalmente no tenemos problema en ver la causalidad directamente. Si pegamos una patada a una pelota, sale disparada. Sin embargo, cuando nos movemos en ámbitos más abstractos o complejos… la causalidad cuesta un poco más de ver.
El ejemplo perfecto lo tenemos en el tiempo atmosférico: son sistemas complejos, con multitud de partes individuales que interaccionan entre sí y tienen efectos que no podríamos saber estudiando cada parte por separado.
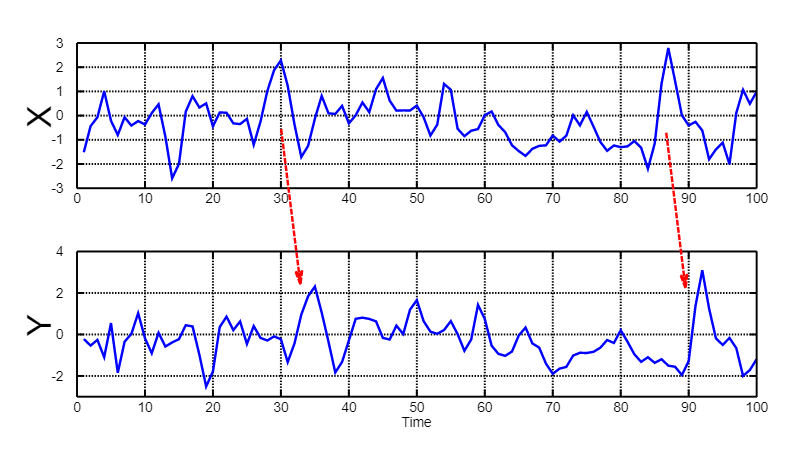
Ilustración de la causalidad de Granger | Fuente: BiObserver, CC BY-SA 3.0, via Wikimedia Commons
Sin embargo, se puede usar la idea de causalidad en cualquier ámbito, no sólo clima.
Exacto. En mi caso, partimos de muchas series temporales que nos dicen cómo evolucionan varios parámetros de forma separada. Con esa cantidad de información, es difícil ver las relaciones que unas cosas guardan con otras.
En estadística, uno de los métodos que usamos para ver esta causalidad es la causalidad de Granger. Más que decir si X causa Y, nos indica si X predice Y. La causalidad de Granger nos da una métrica, un indicador, de cómo de bueno es un parámetro para predecir el comportamiento de otro parámetro.
Y justo lo que estás investigando es un método para mejorar estas métricas.
Sí. Hemos desarrollado una herramientaque permite hacer un análisis de la causalidad, entendida en el sentido de Granger que mencionaba anteriormente: más que decir que X causa Y, nos permite decir que X predice Y. Los detalles tećnicos están en este paper en scientific reports y el código para implementar el sistema está disponible en mi GitHub.
¿Cómo recomendarías usar esta herramienta?
Lo primero es que funciona con series temporales cortas, de 500 puntos. Esto es porque en ese tamaño, la librería es mucho más rápida que la librería de causalidad de Granger que ya existe en Python.
Lo segundo, es que se trata de una herramienta de diagnóstico rápido. En vez de analizar todas las opciones a fondo, nos permite hacer un estudio rápido de la información que tenemos para ver posibles relaciones de causalidad. La idea detrás de la librería es que el usuario dé como input una matriz con las series temporales a analizar y que obtengas como resultado una matriz de causalidad.
Lo que hemos visto es que aplicar esta métrica a diferentes problemas nos da buenos resultados. El ejemplo que comentamos en el paper está relacionado con índices climáticos. Lo que vemos es que reproduce muy bien las relaciones que ya conocemos entre diferentes índices. Entonces, como reproduce bien el conocimiento que ya sabemos, nos permite saber que hace un trabajo robusto… y nos permite explorar aquello que no sabemos. Si vemos dos índices climáticos que en la matriz de causalidad salen como relacionados, ya tenemos un camino por el que tirar: investigar más a fondo si eso es un falso positivo, o es posible que haya una relación de causalidad entre ellos.
La rapidez de la herramienta nos permite hacer un análisis amplio muy rápido. Además una de las características que hemos integrado en el código es bastante única: ver el impacto de una serie temporal con un lag. Esto es algo que no he podido encontrar en las librerías que existen actualmente, al menos en mi experiencia.
Y ahora que vas a estar una temporada en Predictia, ¿en qué estás cacharreando?
De momento no se puede contar mucho detalle, pero tiene que ver con índices de riesgo de fuego y causalidad.
Para saber más, habrá que esperar a que Riccardo termine su estancia con nosotros. ¡Permaneced atentos!